Kafka
- Pub-Sub 모델의 MQ(메시지 큐)이며, 분산 환경에 특화되어 있다.
- LinkedIn에서 개발된 분산 메시징 시스템으로 2011년에 오픈소스로 공개되었다.
Pub-Sub 모델
- Publish-Subscribe
- Message를 전송자가 바로 수신자에게 보내지 않고, 전송자(=발행자/Publish)가 어떤 형태로든 Message를 구분하여 Publish-Subscribe 시스템에 전송하면 수신자(=구독자/Subscribe)가 특정 부류의 Message를 구독할 수 있게 해 준다. 이때 발행된 Message를 저장하고 중계하는 역할을 브로커(broker)가 수행한다.
Message
- Kafka에서는 데이터의 기본 단위를 Message라고 한다.
- DB에서의 row 또는 record에 비유될 수 있다.
Topic & Partition

- Message는 topic으로 분류되고, topic은 여러 개의 partition으로 나눠진다. partition 내의 한 칸은 로그라고 불린다.
- 데이터는 한 칸의 로그에 순차적으로 append 된다.
- Message의 상대적인 위치를 나타내는 값은 offset이다.
- 각 partition은 서로 다른 서버에 분산될 수 있다. 따라서 하나의 topic이 여러 서버에 걸쳐 수평적으로 확장될 수 있으므로 단일 서버로 처리할 때 보다 성능이 우수하다.
- //주의// 한 번 늘린 partition은 절대로 줄일 수 없으므로 partition 크기는 신중히 고려해야 한다.
Producer
- 새로운 message를 생성한다.
Consumer
- 하나 이상의 topic을 구독하여 message가 생성된 순서대로 읽어온다.
- Message의 offset을 유지하여 읽는 message의 위치를 알 수 있다.
- 참고로 offset은 지속적으로 증가하는 정숫값이며, message가 생성될 때 kafka가 추가해준다. partition에 추가된 message는 고유한 offset을 가진다. 그리고 zookeeper나 kafka에서는 각 partition에서 마지막에 읽은 message의 offset을 저장하고 있으므로 consumer가 message 읽기를 중단했다가 다시 시작하더라도 언제든 그다음 message부터 읽을 수 있다.
Consumer group
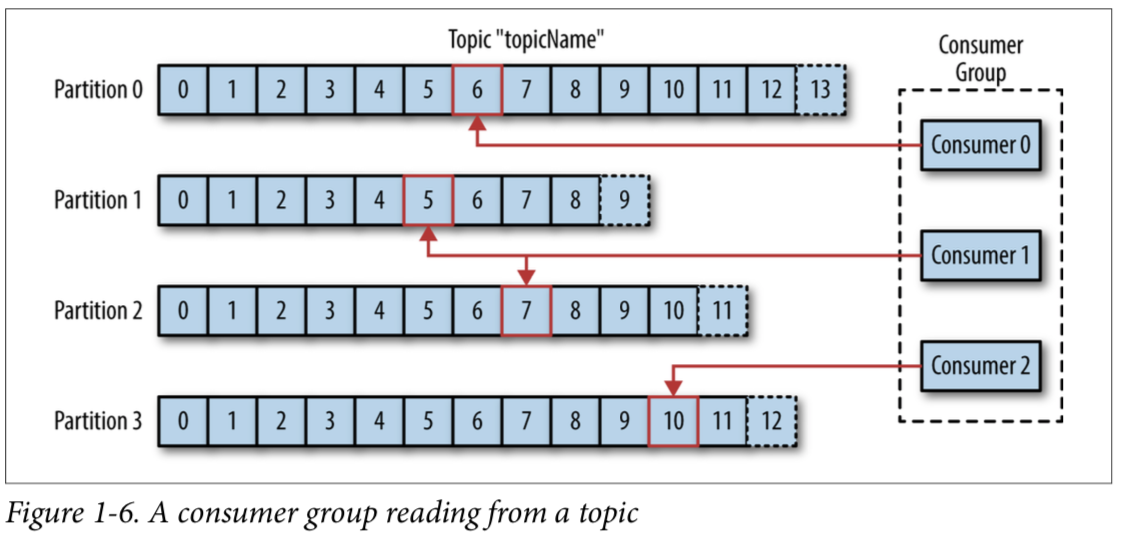
- Consumer group은 하나 이상의 consumer로 구성되며, 한 topic을 읽고 처리하기 위해 같은 group의 여러 consumer가 동작한다.
- 한 topic의 각 partition은 하나의 consumer만 소비할 수 있다. => 반드시 해당 topic의 partition은 그 consumer gorup과 1:N 매칭을 해야 한다.
- case 1) partition 3개, consumer 2개 조합 = consumer 중 하나는 2개의 partition을 소비
- case 2) partition 3개, consumer 3개 조합 = 1:1 매칭
- case 3) partition 3개, consumer 4개 조합 = consumer 하나는 놀고 있음!
- Message가 쌓이는 속도보다 처리하는 속도가 훨씬 빠르다면 1:1 매칭보다는 partition 개수 >= consumer 개수로 설정하는 것이 일반적이다.
- Consumer group은 하나의 topic을 책임진다. 따라서 어떤 consumer가 죽으면 consumer group내에서 다시 consumer들의 partition 소유권을 조정한다. 그래서 다른 consumer가 그 partition을 맡아서 다시 처리하기 시작한다. => 이를 Rebalance라고 한다.
Broker
- 하나의 kafka 서버를 broker라고 한다.
- Broker는 producer로부터 message를 수신하고 offset을 지정한 후 해당 message를 디스크에 저장한다.
- 또한 consumer의 partition 읽기 요청에 응답하고 디스크에 수록된 message를 전송한다.
- 동일한 노드에서 여러 개의 broker를 띄울 수 있다. => Zookeeper는 이러한 분산 MQ의 정보를 관리해주는 역할을 한다. 따라서 kafka 실행에는 zookeeper의 실행이 필수적이다.
- Clustering!! - kafka의 broker는 cluster의 일부로 동작하도록 설계되었다. 따라서 여러 개의 broker가 하나의 cluster에 포함될 수 있으며, 그중 하나는 자동으로 선정되는 cluster controller의 기능을 수행한다. Controller는 같은 cluster의 각 broker에게 담당 partition을 할당하고 broker들이 정상적으로 동작하는지 모니터링한다.
Reference
- https://epicdevs.com/17
- Kafka The Definitive Guide
'Dev > Kafka' 카테고리의 다른 글
| Kafka retention 옵션 - log 보관 주기 설정 (0) | 2020.12.02 |
|---|---|
| Kafka topic 삭제 - already marked for deletion 해결 (0) | 2020.06.11 |
| Kafka 2.1 이상에서 Kafka Offset Monitor 사용하기 - Unknown offset schema version 3 해결 (6) | 2019.12.26 |
| Kafka Monitoring Tool - Kafka Offset Monitor (0) | 2019.12.26 |
| Kafka 외부 접속 허용하기 (0) | 2019.10.07 |


댓글